
#51 - Artificial Intelligence Part 1 - Why we should all take AI seriously.
The first part of a two part series on the impact of AI on financial services


Hi all - This is the 51st edition of Frontier Fintech. A big thanks to my regular readers and subscribers. To those who are yet to subscribe, hit the subscribe button below and share with your colleagues and friends. 🚀
Since Chat GPT came out a couple of years back, Artificial Intelligence or AI in short has become part of the modern cultural zeitgeist. In fact, it is arguably the Zeitgeist and not part of it. I remember my first interactions with AI through ChatGPT and how fascinating it was. In fact I remember showing ChatGPT to some relatives during a family gathering and it was seen as some sort of witchcraft. When a technology has this sort of impact on people, then you know it has the makings of something truly revolutionary. Since then Open AI and other AI research companies have produced even more powerful models such as Chat GPT 4o, Claude 3.5 and Google Gemini. These models have gotten way better and have convinced most of us that indeed AI will impact most industries and how we work. Most people now use ChatGPT on an almost daily basis to help with mundane tasks, plan projects, think through ideas and many other cognitive tasks.
Of course this has led many to re-think how AI will influence financial services. This is a natural step given that Financial Services seem to lend themselves to AI given the industry’s heavy use and production of data. For many decision makers in the financial services industry, this is a topic that is occupying their thoughts and this will only accelerate as the models improve. Every incumbent bank, insurance company or Fintech will soon need to have an AI strategy that is well thought of and is congruent with the trajectory of AI over the medium to long-term. Decision makers will need to answer the following;
What is AI?
Where is AI headed?
Is it truly a General Purpose Technology like Electricity, the Internet or the Steam Engine?;
How should I think about it as a leader in the Financial Services Industry?; and
What are the practical implications to my business and industry;
It’s clear to me that over the long-term, the next two years will be very important for incumbent leaders when it comes to defining their AI strategy. The wrong decisions could lead to a material destruction of shareholder value and a loss of competitive relevance. The article will be a two part series.
The first article will be a breakdown of AI in simple terms and a framework for thinking about what AI is and where it’s headed;
The second one will be a more practical exercise on what some of the implications will be (Hint it’s not only advanced chatbots);
Introduction to AI - The history of Artificial Intelligence
The concept of intelligence is very broad and often very controversial. Intelligence can be thought of as the ability to apply knowledge and skills, to synthesise information and derive new insights from that information. It can be thought of as the ability to think, recognise patterns and create new knowledge. The definitions are vast, but ultimately everyone has an intrinsic understanding of what intelligence is. Everyone intuitively understands that there are different types of intelligences and chiefly, that levels of intelligence vary between people. For our sake and the sake of this article, it’s important to focus on intelligence as the idea of cognitive ability. The raw ability to take in new information, learn from it, identify patterns, create new insights and use those insights and information to make decisions.
The human condition is broad and complex. Human beings have complex emotions, feelings and a wide array of personalities. This is compounded by neurological and physiological diversity that makes the idea of what it means to be human rich and complex. Nonetheless, it’s important to have in mind that if there’s one aspect of our make-up that has advanced our situation in life or the human condition in general, it’s our intelligence. It’s our ability to learn, communicate, store information and create new knowledge that has moved us from our hunter and gather origins to our new existence full of technological advancements. If I were a scientist, I’d be more keen on replicating this sort of intelligence rather than replicating feelings and emotions which, as important as they are to the human condition, are arguably not critical for the advancement of “scientific knowledge”. This of course is a completely debatable take, but it’s not controversial. The point is simple, if there’s a direct link between cognitive ability or IQ and scientific advancements, then increasing overall IQ is of direct value to the human race. The idea then of augmenting our intelligence or creating another form of intelligence is a valuable research goal.
This brings us to the work of Alan Turing who many consider to be a pioneer of Artificial Intelligence. In 1950, he published a seminal Article called “Computing Machinery and Intelligence”. In it he starts by stating “I propose to consider the question, ‘Can Machines Think?’”. He continues to lay out a framework for testing this question. Indeed, this is a very open-ended question and given such generality, he states that this question can be answered using a Gallup Poll. To be more thorough, he proposes what he calls the “Imitation Game”. In the imitation game, there is a Man, a Woman and an Interrogator. The interrogator is meant to find out which of the two is a man and which one is a woman. The man and the woman have an incentive to deceive the interrogator. Moreover, it is designed in such a way that the interrogator cannot infer their sex through their voice, handwriting or any other clear give-away. In fact he states “In order that tones of voice may not help the interrogator, the answers should be written, or better still, typewritten. The ideal arrangement is to have a teleprinter communicating between the two rooms. Alternatively the question and answers can be repeated by an intermediary.” Turing then finishes the introduction to this paper by asking
We now ask the question, ‘What will happen when a machine takes the part of A (the man) in this game?’ Will the interrogator decide wrongly as often when the game is played like this as he does when the game is played between a man and a woman? These questions replace our original, ‘Can machines think?’
Turing further gives the condition that the only machine that can participate in this game should be a digital computer and that moreover, it should have the basic capabilities of storage of information, execution of commands (algorithms) and control meaning that the commands/instructions should be followed in a sequential manner..
This intelligence framing of the question “Can Machines Think” was arguably the spark that lit the scientific body of research that we now call Artificial Intelligence. Simply, could computers ever get to the point where they were indistinguishable from man?
In the summer of 1956, some leading researchers inspired by Turing and led by John McCarthy, Marvin Minsky, Nathaniel Rochester and Claude Shannon met at Darthmouth College. This came to be known as the Dartmouth Conference and aimed to explore the possibility that “every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.” This conference created the foundations for modern AI research exploring the idea that machines could mimic human thought.

This detour in the box above was necessary to understand the constraints in which AI researchers at the time operated in. Due to these constraints, the 50s saw techniques such as rule-based systems and symbolic reasoning utilised to “mimic human thought”. These techniques involved using human-defined rules and specific actions that the system would take to execute commands as well as the use of symbols to represent concepts. These techniques were proposed to work with the existing computing capacity. Think simply of trying to mimic intelligence by creating a rigid set of rules e.g. when you see x, respond with y.
In the 1960s, additional techniques were added to the AI research tool-kit such as early forms of machine learning. The challenges with rule-based systems and symbolic reasoning was that they suffered from rigidity, lack of scalability and brittleness given that they were based on hard-coded rules and symbols. They didn’t mimic how humans actually think. A key development therefore was the idea of machine learning. The insight here was to move away from rigid rules or symbols and utilise data instead. Computers (machines) would be fed data and using statistical models would derive patterns from the data and therefore learn from the data. The technical term for this is to “make inferences”. Think of machine learning as a large statistical regression model.
However, the high expectations that had been set in the 50s through the Dartmouth conference failed to materialise into any significant breakthroughs. Simply, the techniques were inadequate and the computing power was far from ready to support the lofty expectations of the earlier years. An AI winter ensued in the 70s characterised by a reduction of investments and scientific interest in the area of AI. Machine learning for instance needed much higher processing capacity and storage for it to give meaningful results.
Little progress was made in the 80s as well. There was the introduction of Expert Systems which relied on large data sets of ‘expert knowledge’ which were used to define advanced rules that would guide the model’s output. Think of taking in the opinions of top legal minds about specific topics in law and storing these in a database to be used for “legal research” in the future. These models while novel still suffered from the same fate of the earlier rule-based and symbolic models. They were brittle and didn’t scale. Additionally, they didn’t mimic human thought.
Progress continued to be made in the 90s with researchers such as Geoffrey Hinton playing a key role. The key breakthrough was the advancement of Neural Networks which would play a key role in AI as we know it today. Neural networks take inspiration from the way the human brain works. They contain three key elements;
Neurons (Nodes) - Each node is a processing unit that takes in inputs and produces outputs based on a mathematical function (algorithm). They are organised in layers which are interconnected;
Layers - Think of these as levels that the data has to pass through. Data would get ingested through the input layer and go through different levels with each level representing a specific function. For instance, if a picture went through the input level, the first level would capture edges, the second would capture colours and so on until the model has learned some fundamental features of the image;
Weights and Biases - Each connection between neurons has a function that helps determine the importance of that input in the overall decision making process. In the case of the image, it could be that the weight states that the edges are not as important as the faces in processing the image. This is an extreme over-simplification but it is good enough for what we’re trying to do.
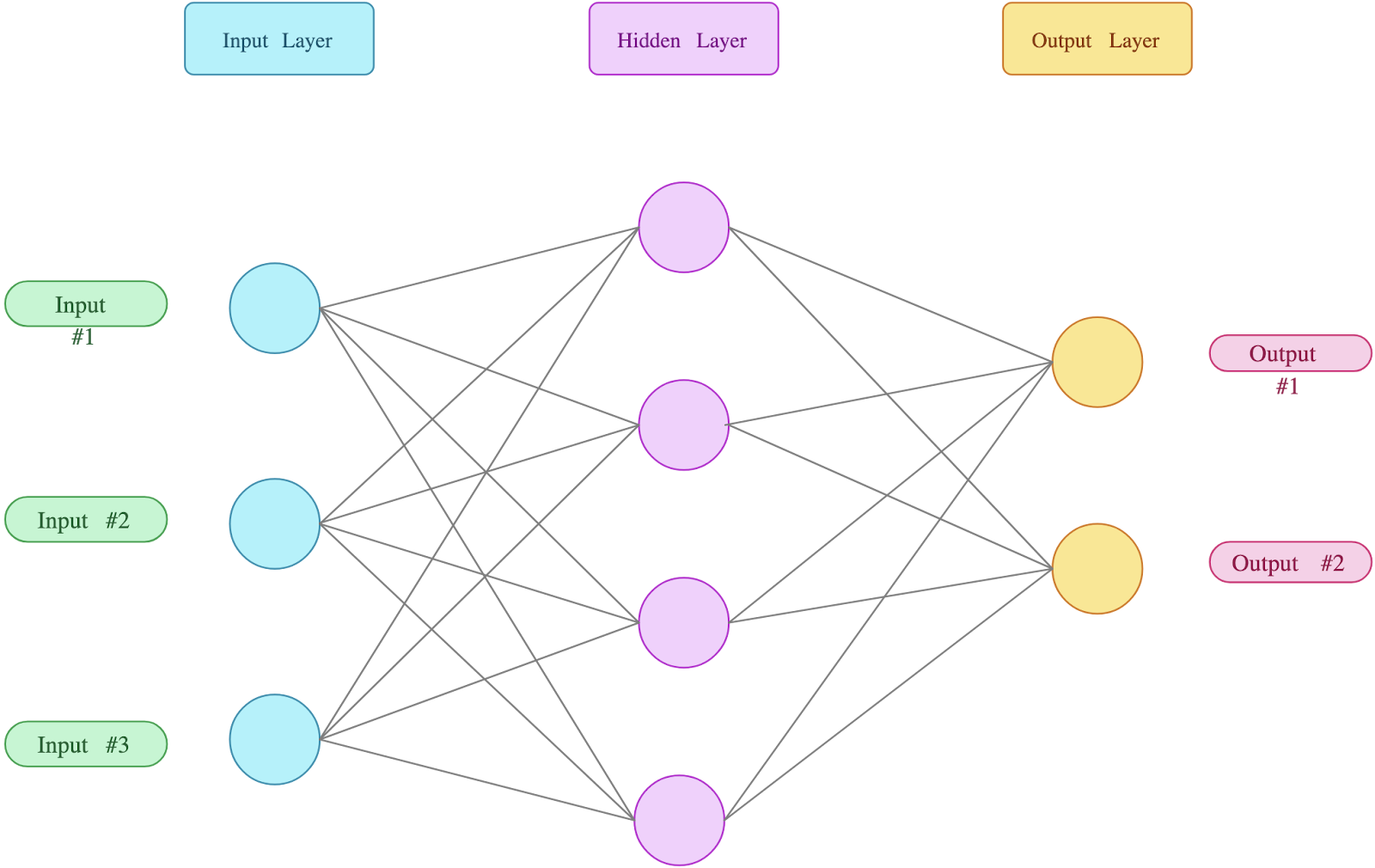
The diagram above is an example of a neural network. Each circle is a node and there are three layers. The input layer, the hidden layer and the output layer.
💡 The diagram above has 26 parameters. Note that a human brain is estimated to have roughly 100 trillion neural connections or parameters. It’s important to keep this in mind when you hear a model having 1 trillion parameters.
Neural networks learn through training which involves feeding the model large amounts of data and automatically adjusting the weights to reduce the errors the model makes in its predictions. The automatic adjustment of weights uses a technique called back-propagation. Simply, think of this as a sound engineer adjusting the dials of a mixer until the right sound comes out just that this is happening automatically. This led to the growth of deep learning which is a subset of machine learning. Deep learning uses multi-layered neural networks thus the term ‘deep’ to learn and model extremely large and complex data. A key difference between machine learning (which we described earlier as basically a regression model) and deep learning is that deep learning can take in unstructured data. Deep learning solved the constraints that earlier models faced i.e. brittleness, rigidity and lack of scalability. With deep learning, in theory you could scale to infinity by adding additional layers and nodes. Deep Learning enabled a field in AI called Natural Language Processing to really advance because “natural language” in the form of text could be fed into the models and they would in turn be able to detect patterns in natural language. This enabled a lot of the translation and language detection capabilities that we use today.

Progress continued to be made in the 2000s from a data, algorithm and compute perspective leading to Ray Kurzweil writing his famous book “The Singularity is Near”. In the book, he defined the Singularity as a “future period during which the pace of technological change will be so rapid, its impact so deep that human life will be irreversibly transformed”. He went on to state “The key idea underlying the impending singularity is that the pace of change of our human-created technology is accelerating and its powers are expanding at an exponential pace. Exponential growth is deceptive. It starts out almost imperceptibly and then explodes with unexpected fury… unexpected, that is, if one does not take care to follow its trajectory.” For the sake of this article, Kurzweil’s book is important because it predicted that human level intelligence would be achieve by the end of this decade.
Fast forward to 2012 and a major breakthrough was made in the ImageNet challenge. ImageNet was a database of over 14 million labelled images categorised into 1,000 categories. Each year from 2010 to 2017, ImageNet held a competition whose aim was to classify images into over 1,000 categories. The goal was simply for people to develop models with low error rates i.e. the percentage of times that an image is mis-categorised. In 2012, AlexNet, a deep learning model that was designed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton won the competition by significantly out-performing all other models. This stunning victory made the scientific community take notice of deep-learning.
💡Machines they just want to learn - Ilya Sutskever
Since then, billions of dollars have been poured into Deep Learning and scientific interest has increased in leaps and bounds. Since AlexNet, the following major milestones have been achieved;
The pace of innovation in AI led to the formation of OpenAI in December 2015 by Elon Musk, Ilya Sutskever, Sam Altman, Greg Brockman and Wojciech Zaremba. The mission behind OpenAI was to ensure that Artificial General Intelligence, which was expected to be smarter than human beings, benefited all of humanity. It was seeded with US$ 1 billion which at the time was a record amount of investment into a non-profit. Key backers included the likes of Reid Hoffman, Peter Thiel and other influential Silicon Valley Entrepreneurs;
In 2017, Researchers from Google invented “Transformer” technology in their paper “All you need is attention”. Prior to Transformers being introduced, models would read sentences word by word. Intuitively, this doesn’t make sense because we as humans read entire sentences rather than reading word by word. This is how we gain context. The invention of Transformers enabled sentences or even whole paragraphs to be read in their entirety thus enabling a model to have ‘attention’.
These building blocks coupled with advances in Reinforcement Learning through Human Feedback (RLHF) enabled OpenAI to launch ChatGPT in November of 2022. The GPT stands for Generative Pre-trained Transformer. ChatGPT was an AI that used Large Language Models and Natural Language Processing to generate content, thus the ‘Generative’. It brought the years of AI research that went unnoticed amongst every day folk into the limelight and made everyone pay attention. Gaining over 100m users in just about 2 months, it set a record for the fastest adoption of a new technology. This moment sparked a flurry of activity in AI with companies across the world trying to figure out their AI strategy.
Current State of Play with AI
So where are we with regards to AI and where are we headed. This is a crucial question as the answer should inform strategy across the business world. If it achieves its promise, then it creates a breakage in the economic means of production. Such a breakage can lead to winners and losers not only in business but arguably even on a sovereign level. Technology is often a very emotive subject, particularly impactful technology such as the internet, the steam engine or even electricity. Incentives always emerge that drive extreme opinion on either side. Some argue that the new technology is completely useless and will not change anything. Others argue that the new technology will completely change the face of humanity. Human beings tend to resist massive technological change as it brings to question our value on earth. Always the truth is somewhere in between, although with AI it leans towards the latter.
To understand where this technology is headed, we need to simply remember the drivers of AI growth over the years. Advancements in AI have been driven by;
Growth in Computing Power;
Algorithmic Advancements - Remember journey from Rule Based Systems to Deep Learning?
Growth in Data.
The best coverage I’ve seen on this is an essay series called “Situational Awareness” by Leopold Aschenbrenner that was written in June, 2024 and is a must read. Leopold is a former researcher at OpenAI and in his own right is a genius. Leopold went to Columbia University at 15 and graduated Valedictorian at only 19. He won the prestigious Tyler Cowen Award from Emergent Ventures and is simply a genius. In “Situational Awareness”, Leopold outlines his vision of AI and how he expects that we should have Artificial General Intelligence by 2027 i.e. where AI’s are as smart if not smarter than human beings. Thereafter, we should see Super-intelligence following in short order where Super Intelligence refers to an AI that is a magnitude of times smarter than humans. It’s a detailed walk-through of what essentially is how the “scaling law” will play out. At this point remember Ilya Sutskever’s words - “The models, they just want to learn”. Or Kurzweil saying “the pace of change of our human-created technology is accelerating and its powers are expanding at an exponential pace.”
In the article he decomposes the drivers of growth as the following;
Growth in Compute;
Algorithmic Efficiency;
Unhobbling
💡 Concept Check. Growth in AI capabilities are measured in Orders of Magnitude (OOMs). 0.5 OOMs is 3x, 1OOM is 10x, 1.5 OOMs is 30x, 2 OOMs is 100x and so on. Simply 0.5 OOMs is a tripling of magnitude therefore 2.5 OOMs is 300x. So if something grows by 1 OOM, it has 10x, 2 OOms has 100x’d and 3 OOMs has 1,000x’d.
Growth in Compute
Compute can be broken down into both advancements in the underlying processors (GPUs) and the scale of the data centres that are being used to train them. Think of this as compute productivity and sheer gross computing power.
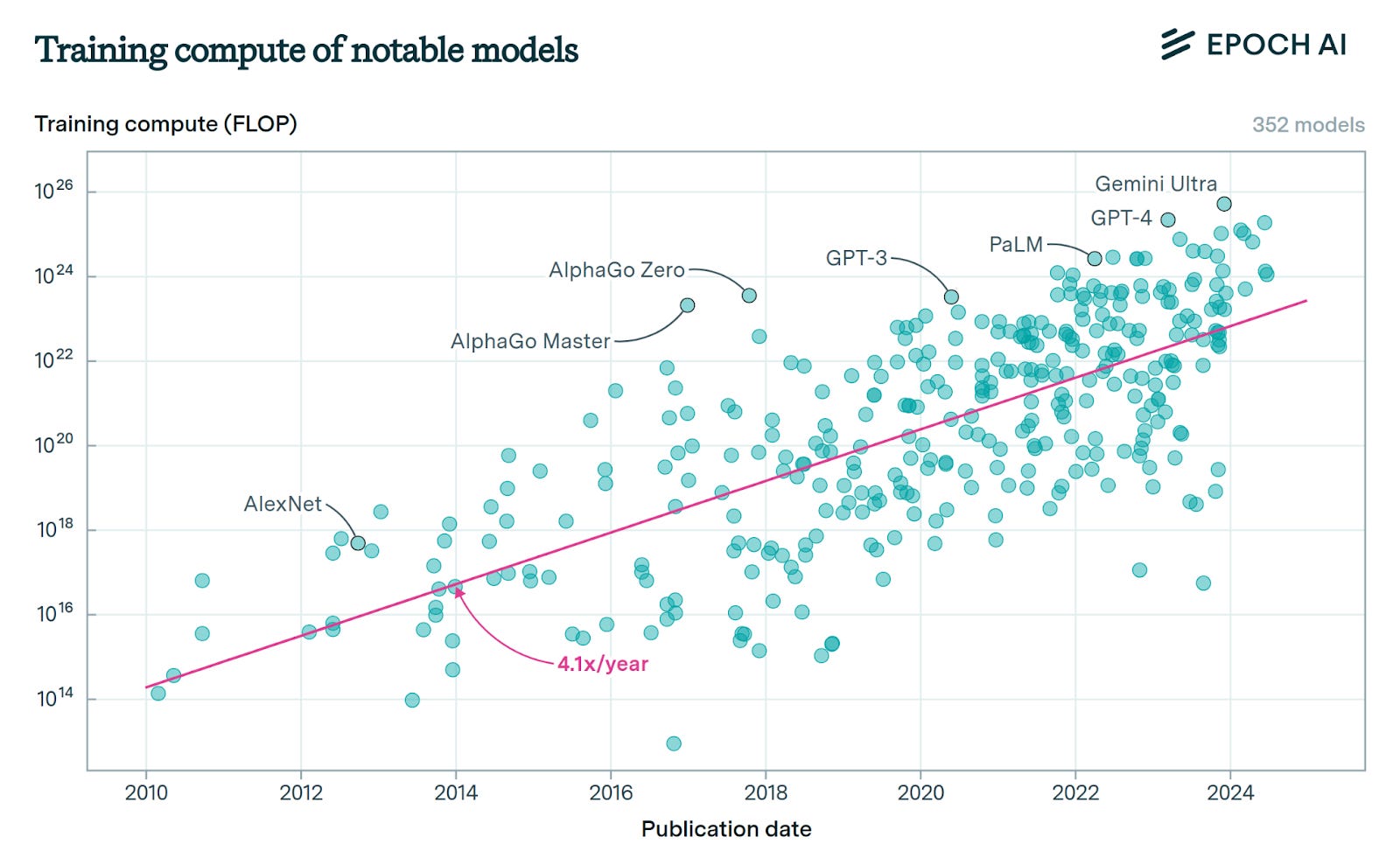
Source: Epoch AI
The data on compute growth obtained from Epoch AI shows that it has been growing at a rate of 4.1x a year. This has largely been driven by growth in total spending i.e. size of data centres rather than improvements in hardware although the latter have played a part. It is estimated that ChatGPT 3.5 which was a 175 billion parameter model cost between US$ 4 and US$ 12 million to train. Chat GPT4 which is a larger model with close to a 1 trillion parameters cost above US$ 100m to train. There is talk of upcoming models costing US$ 10 billion to train and a recent interview of Eric Schmidt (interestingly the original was deleted) suggests that Sam Altman is looking to spend close to US$ 300 billion to train a model.
The graph below from an excellent talk by Mirella Lapata shows that the human brain has 100 trillion parameters. This suggests that we need at least an 100x or 2OOMs improvement in the size of the models to get to the level of a human brain.

A move to a US$ 100 billion training cluster (data centre) would lead to 3 OOMs growth which would suggest that we’d have a quadrillion parameter model. The question is what would justify such investments given all the talk of an AI hype bubble. The following frameworks have been the most convincing to me;
Eric Schmidt suggests that Silicon Valley investors and entrepreneurs think that there is an infinite return to multiplying human intelligence and therefore any investment is justified;
Leopold gives an example of how past investments in General Purpose Technologies have also been transformational;
At the peak of British Railway Investment, the United Kingdom invested 7% of its GDP in Railways. 7% of US GDP would be US$1.7 trillion and there’s talk of a US$ 1 trillion cluster;
At the height of US Investments in Telecoms infrastructure in the mid 90s, over US$ 500 billion was invested in laying fiber optic cables, switches and other associated infrastructure.
Simply, there’s precedent in heavy investment once a General Purpose Technology has been identified. If compute is to drive growth in AI, and if key decision makers believe that AI is transformational, then investment will follow.
In terms of advancements in hardware, data shows that GPU price performance has been doubling every 2.9 years and this trend is expected to continue. Simply, by 2027, a US$ 10 billion investment would give you the same output as a US$ 30 billion investment today. The trend in computing advancement should be expected to continue.
Algorithmic Efficiency
This can be thought of as innovations that enable models to perform better in a task whilst utilising less computing resources. We have already covered the progress from Rule-based systems to Deep Learning and within deep learning, advances such as transformers that enabled even better performance. Leopold makes the case that there has been an improvement of 0.5 OOMs per year or 3x a year improvement traditionally in algorithmic efficiency using data from ImageNet. If this is extended, then you have a 2 OOMs improvement or 100x improvement in model efficiency. If this is coupled with the growth in compute, then you can see how a 5 OOM overall improvement in the performance of these models is possible within a few years. This is simply a bet on human ingenuity, just like in Moore’s law, the bet is always that we have hit the limit of ingenuity and the trend can no longer continue. However, with each year, we make new breakthroughs and discoveries. Leopold therefore argues that this should continue.
Unhobbling
When the first ChatGPT came out, one of the biggest challenges it had was “hallucination” i.e. saying things that simply don’t make sense. This is because LLMs work on the basis of predicting the next word in a sentence and moreover are trained to respond. Imagine if you asked your 11 year old nephew or niece to explain the role of geography in defining Africa’s trade routes and you told them that they must answer the question immediately. They will respond with gibberish. This is how hallucination happens. Clearly, this is not how humans learn and communicate. If you were given an essay to write about “The Soweto Uprising”, you would create a plan of action, do research, verify your sources and then write your article. Unhobbling is simply the work of enabling AIs to work smarter and there are a number of ways that researchers are working to “unhobble” these models.
Chain of Thought Reasoning - Teaching the model to break down a plan of work into a logical sequence of steps just like how you would solve a complex math problem. Eric Schmidt in a recent interview suggested that the next vintage of frontier models will be able to process 1,000 steps in Chain of Thought Reasoning;
Scaffolding - This involves models dividing up a task amongst themselves just like how we humans work in groups. One would handle one task, and another one would handle a separate task;
Tools - If you were given a construction project, you would definitely make use of Project Planning software. At the very least Excel. Similarly, unhobbling models would involve teaching an AI to use various tools such as Excel, Notion and others to execute a task. The latest version of Models uses websearch when giving answers;
Post-training improvements - Simply making small adjustments to the model after training. Leopold estimates that post-training improvements in Chat GPT 4 made it improve by over 10% percentage points on a number of math tests.
Putting it all together
The CEO of Nvidia Jensen Huang in an interview with Roelof Botha of Sequoia said the following.
Now with AI, we’re advancing at the chip level, at the system level, at the algorithm level, and also at the AI level. And so, because you have so many different layers moving at the same time, for the very first time we’re seeing compounded exponentials. And, if you go back and just look at what, how far we’ve gone since ImageNet, AlexNet, we’ve advanced computing by about a million times. Not a thousand times. A million times. Not a hundred times. A million times. And we’re here now compounding at a million times every ten years. - Jensen Huang
The numbers show that AI is on course to grow over 10,000x conservatively. If ChatGPT was as smart as a clever high school student, by 2027, we should see AI that is smarter than an exceptional PHD student. Unhobbling will ensure that we move away from basic chat bots that hallucinate to a new form of engagement that can multi-task and run complex projects.
The history of AI has parallels in human life. Just like how humans learn, we benefit from a number of internal and external factors that make us smart and competent. Our brains grow naturally over time of course up to a point similar to how compute has grown. We are educated enabling us to produce more with less, similar to how algorithmic improvements have driven AI. Further, we learn skills and mindsets that further differentiate us as humans. The scientific method and enlightenment for example was an unhobbling of human capacity. So the growth of AI is somewhat natural and can be understood in the context of how we humans improve over time. However, that's where the parallels stop. With AI unlike humans, the compute is unlimited whereas our brains have a natural limit. Moreover, AIs can work throughout and can be replicated whereas we humans get tired easily. AIs can be trained on all human knowledge and create additional knowledge whereas no human can be trained on all human knowledge.
Critiques;
One of the more convincing critiques about AI and particularly the path towards AGI comes from French scientist Francois Chollet. Francois created the ARC test which is a very simple elementary pattern matching exercise. The only trick is that these patterns are novel and thus have not been used to train LLMs yet. All the LLMs seem to fail these tests leading Francois to argue that these models are not intelligent rather they are great at predicting the next text and memorising

Source: The Dwarkesh Podcast
Be that as it may, my thinking is that people won’t generally care about what’s happening in the background. People will be more concerned about the output. It reminds me a bit of the big theme of decentralisation and software. People don’t care that Facebook is centralised, generally they care that it works.
What Next;
We’ve understood the history of AI, we have understood the drivers of AI and we have a good understanding albeit controversial of where AI is headed. How then should we think of AI especially as we approach AGI? The best answer I’ve seen was given by Mustafa Suleyman who is the current CEO of Microsoft AI and former co-founder of Deep Mind and Inflection AI. He refers to AI as a new Digital Species that has special characteristics different from human beings. It is a digital species that is invisible to us but that we will interact with on a daily basis. It has the potential of completely altering the course of humanity as Kurzweil predicted in both good and bad ways. Commercially, this new digital species will have far reaching implications in not only how businesses are currently run, but in how industries are structured.
AGI and Super Intelligence
Top minds such as Bill Gates, Carl Shulman, Sam Altman, Eric Schmidt, Demis Hassabis and Mustafa Suleyman have all predicted AGI within a very short-time at least within this decade if all holds constant i.e. if nothing unforeseen happens. Leopold extends this further and predicts that once we have AGI, then human AI researchers will be replaced by AI researchers. Given that AI researchers can work full time and can be infinitely multiplied then we should have another AI explosion that leads to a super-intelligence. An AI that is magnitudes of times more intelligent than human beings. The capabilities of Super-intelligence will create capabilities that are the stuff of science fiction. Advanced medical research will unearth new cures for diseases, military capabilities will approach new epochs that we can’t imagine and life as we know it will change completely. I’m not a science fiction writer and the purpose of this article is not to speculate on super-intelligence. The only reason I’m pointing this out is because, if this is true, then we need to think of the AI industry in the same way we think of the Nuclear industry. It will be tightly controlled by one or two governments at most with some form of Mutual Assured Destruction guiding major power relationships. More than likely, it will be one that rules them all.
Sovereign and Market Structure with AGI - Insert Oppenheimer Quote
Sovereign Structure
In the movie Oppenheimer, shortly after they detonated the bomb (Trinity), Edward Teller and Robert Oppenheimer are having a discussion about its implications. The concern Edward has is about whether the US government will use it and what the consequences would be. They’re specifically discussing Szilard’s petition that was encouraging an international treaty of sorts to put the genie of the A-bomb back in a bottle. Edward asks Oppenheimer what he thinks about the petition. Upon reflecting Robert Oppenheimer responds, “Once it’s used, nuclear war and all war becomes unthinkable”. Edward retorts “until someone builds a bigger bomb”. Superintelligence could be the bigger bomb.
If the trends in AI continue then at some point governments will have to take over. A super-intelligence will be a critical national asset as militarily, it would be able to dominate warfare to a level never before witnessed. A super-intelligence can be sent to knock out an entire country’s nuclear capabilities and retrieve all military intel from an adversary. Eric Schmidt alludes to this stating in a Stanford interview that there is a 10 to the power of 26 Act that states that any Model that has a capacity of 10^26 parameters has to be reported to the US govt. He adds that AI capacity is a factor of access to computing and access to top brains. With this in mind, there are only two countries that would likely matter, the US and China. Both have access to Computing capacity with China having an advantage in terms of their industrial capacity to install electricity. Nonetheless where it matters, access to Chips and AI talent, the US is years ahead of China. The Semiconductor ban under both Trump and Biden was simply an Nvidia Ban i.e. denying China access to Nvidia chips. If this continues then the undeniable conclusion will be a return of an even more unipolar world with the US at the apex with even greater capabilities of controlling the world. It’s going to be an American century like never before. They will be able to use this digital species to dictate how the world runs. The concept of sovereignty will continue to lose meaning.
Industrial Set-Up
Given the sums that are being floated around for training the next generation of models that run in the hundreds of billions of dollars, then there will be only a handful of players that will survive in the industry. The current leaders are Google, Open AI & Microsoft, Anthropic and Meta. This is likely to continue and maybe there should be some consolidation down the line with two to three players involved. Given the close inter-play between government and technology, then there should be some version control in place as regards to which models are accessed by who. I foresee an oligopoly structure that will dictate how the AI industry works in much the same way that the oil industry works. Oligopolies naturally give way to cartel like behaviour as seen with OPEC. There will be either tacit or overt price collusion given that the returns to AI will accrue to the US. The way to think about it is that every individual and company in the world will pay for AI much as how we all in some way pay for fuel. The difference now is that all the oil will be produced in one country and controlled by two to three companies. Nvidia will supply these two companies all their drilling equipment. If this is the case then we’re just scratching the surface on how big some of these companies could get. The only way this doesn’t happen is if open source models become as good as the frontier models. However with the amount of money that needs to be invested, I’m not sure how probable this scenario will be.
In summary, individuals and companies will buy a controlled version of AGI whilst governments based on their alignment with the US will get similarly controlled versions of AGI, likely more advanced than what companies and individuals can buy. The sales model will look a bit like how enterprise software is sold by giants such as Microsoft and Google. Think enterprise cloud sales with customer success teams that guide implementation, governance and support.
Can we just lock it up?
One argument that can be made is that at some point, if it gets too powerful, then governments should just lock it up in the way you’d put the genie back in a bottle. Nonetheless, the game theory around this suggests that the incentive to win both at a sovereign and company level will drive ever more investments for fear of losing out. If the USA slows down, then the fear is that China could overtake it and take the spoils of winning in super-intelligence. This simply won’t be tolerated.
Once the AGI is delivered commercially, a similar situation can occur at our level i.e. smaller countries in Africa, Asia, Latin America, Europe and the Middle East. The game theory similarly suggests that failure to adapt to AGI at a sovereign level could result in some military, intelligence and industrial disadvantages. There will therefore be a drive by fast moving countries to integrate AI into their governance, military, security and industrial structures to remain competitive. Countries such as India, South Korea, Singapore, South Africa, Brazil and Chile are all working on AI policy.
One could argue that industry associations such as banking or insurance associations could throttle AI deployment to protect their industries. This is a very strong possibility and one that we’ll touch on in the next article. Nonetheless, there will be AI adoption in other industries such as manufacturing, telecoms and trade sectors. This in itself will create competitive pressure for these industries to adapt to AI. Moreover, the game theory also suggests that where there is a competitive market, the spoils of an AI advantage will drive one player to go for it thus making it logical for all the other players to embrace it. We’re already seeing this with significant investments by large banks in AI experimentation.
Agents as the UX of AI
Given that deep-learning was advanced on the back of Natural Language Processing and Large Language Models, a chatbot was the most natural way of enabling human beings to interact with AI for the first time. However, chatbots are not AI. With the earlier discussion about unhobbling, specifically enabling chain of thought reasoning, the use of tools and scaffolding, it’s clear that we will have AI agents. What that means is that AIs will somehow be integrated into our daily life through a player such as Google, Apple or Microsoft unifying our data. This will then lead to agents being able to perform complex tasks on our behalf. We’ll tell the AI that we’d like to build a house and the AI will run a search on land prices, create a project plan on Google Sheets, check out the best mortgage products in the market, seek out the best contractors and handle all legal work just occasionally seeking out our input. This in my view is not far away.
To sum it up;
AI is real and not a passing fad - don’t think of AI they way you thought of Bitcoin;
The trajectory shows that AI will keep getting better but now at a much accelerated pace, our human brains struggle with exponentials;
Not having an AI strategy is arguably irresponsible and this is something that shareholders should drive;
As a worker in the Financial Services industry, understanding all this will enable you to position yourself strategically for the coming AI tsunami;
What to expect in the next edition
Now that we have a clear understanding of what AI is and where it’s headed, we can now make sober predictions on how the financial services, specifically banking, is likely to be impacted and how CEOs, Chairmen and Executives should approach AI.
As always thanks for reading and drop the comments below and let’s drive this conversation.
If you want a more detailed conversation on the above, kindly get in touch on samora@frontierfintech.io
I’m open for advisory roles but there are only a few spots left. Kindly reach out on samora@frontierfintech.io if you’re keen on having a discussion about advisory work.